I work with AI every day. I call APIs that use it. I build feature on top of it. I read about it in every newsletter that lands in your inbox.
But here's a question that is surprisingly hard to answer precisely: what is actually AI?
Not in the marketing sense. Not "intelligent systems that transform business outcomes" or whatever the vendor pitch says. How do you define it in a way that actually helps you make better decisions when you're building software?
I spent a while not being able to answer that cleanly. I could use AI tools fluently. I could not explain, with precision, what separated "AI" from "a really long if/else chain". It turns out that distinction matters a lot because the "AI" gets applied to both, and knowing which one you're dealing with changes everything about how you build, debug and trust a system.
This is the article I wish I'd had at the start.
The Problem With the Word "AI"
Let's start with why the term is so confusing: "AI" describes a goal, not a method.
It describes the destination, a machine that does something requiring intelligence, without saying anything about how you get there. Two engineers can both legitimately claim their product "uses AI" even though one built a system of hand crafted if/then rules and the other trained a neural network on millions of examples.
This isn't semantic pedantry. It has real consequences.
When a vendor says their product is "AI-powered", that tells you almost nothing technically. When a job posting says "experience with AI required, it could mean prompt engineering, classical machine learning, or writing business rules in a decision engine. When your team debates whether to "use AI" for a feature, you're probably talking past each other because you each have a different method in mind.
The unlock is understanding that AI is the umbrella, and under that umbrella live several fundamentally different approaches: each with different strengths, limitations, costs, and failure modes.
Let's walk through them chronologically, because the history is the clearest way to understand why each approach exists.
Era 1: The Rulebook Approach (1950s-1980s)
The earliest AI researchers had a reasonable hypothesis: intelligence is basically expertise, and expertise is basically knowledge. If you could encode enough knowledge as explicit logical rules, surely you'd get intelligent behavior.
This produced what became known as Expert Systems: programs that could diagnose diseases, configure computer hardware, give legal advice, and solve engineering problems, all by following thousands of hand-crafted if/then rules written by domain experts.
The structure of an expert system is simple:
A knowledge base: a collection of facts and rules ("if the patient has a fever AND a cough, consider infection")
An inference engine: the logic that applies those rules to new situations to reach conclusions
And for a while, this worked remarkably well. Expert systems were formally introduced around 1965 by the Stanford Heuristic Programming Project led by Edward Feigenbaum. By the 1980s, corporations worldwide had adopted them, and the AI industry had grown from a few million dollars in 1980 to billions of dollars by 1988.
Then the ceiling appeared.
The problem wasn't the idea, it was the brittleness. These systems could only reason about things they'd been explicitly told. Step outside the rulebook and they either failed silently or produced nonsense. As the Wikipedia article on AI history describes them directly: they were "difficult to update, they could not learn, and the were 'brittle' — they could make grotesque mistakes when given unusual inputs."
Maintaining them was a nightmare. As the problem space grew, the number rules exploded. Rules started conflicting with each other. New hires had to read thousands of conditions to understand a single decision. And the moment the real world changed (new regulations, new products, new customer behavior), the rulebook was instantly out of date.
By the late 1980s and early 1990s, the market had lost confidence. Funding collapsed in what became known as an "AI winter". Over 300 AI companies shut down, went bankrupt, or were acquired by the end of 1993.
The lesson: For problems well-defined, stable rules and limited scope, a rules engine is still the right tool. Simple, transparent, auditable, fast. But the moment the problem involves open-ended judgment, ambiguous language, or patterns too complex to enumerate, rules hit a hard ceiling.
Era 2: The Brute-Force Approach (1980s-2000s)
While experts systems were booming and then collapsing, a parallel track of AI research was pursing a different strategy: not encoding knowledge, but searching.
The most famous example is IBM's Deep Blue: the chess computer that became the first to defeat a reigning world champion under tournament conditions, beating Garry Kasparov in May 1997.
How did Deep Blue work? Not by learning. Not by understanding chess the way Kasparov understood it. According to IBM's own account, "Deep Blue derived its chess prowess through brute force computing power", evaluating up to 200 million chess positions per second, using 32 processors running in parallel.
The Wikipedia article on Deep Blue is even more direct: "Deep Blue used custom VLSI chips to parallelize the alpha-beta search algorithm... The system derived its playing strength mainly from computing power."
This is fascinating for what it reveals about the word "AI".
IBM at the time, actually didn't claim Deep Blue used artificial intelligence, they just described it as a computing achievement. A 1997 AAAI paper pushed back on this, arguing that the chess-playing goal, doing something that requires intelligence, qualifies it as AI regardless of the method used.
Both sides were right in their own way. Deep Blue achieved an intelligent-seeming outcome. But it did so through raw computational search, not through anything resembling understanding. Ask Deep Blue to play checkers and it's helpless. Show it a chess position it couldn't have computed and it has no intuition to fall back on.
This approach hit a different kind of wall: combinatorial explosion, You can brute-force chess because it has a bounded set of legal moves. You cannot brute-force "understand this sentence" or "recognize this face" as the search space is infinite and unstructured.
The lesson: Search-based AI is powerful in constrained, well-defined problem spaces. But intelligence in the real world requires dealing with ambiguity, context, and patterns that can't be enumerated and search-based approaches can't cross that line.
Era 3: The Learning Approach (2000s - Today)
Here's the moment the frame shifts completely.
Instead of asking "how do we program a machine to behave intelligently?", researchers started asking "how do we build a machine that learns to behave intelligently from examples?"
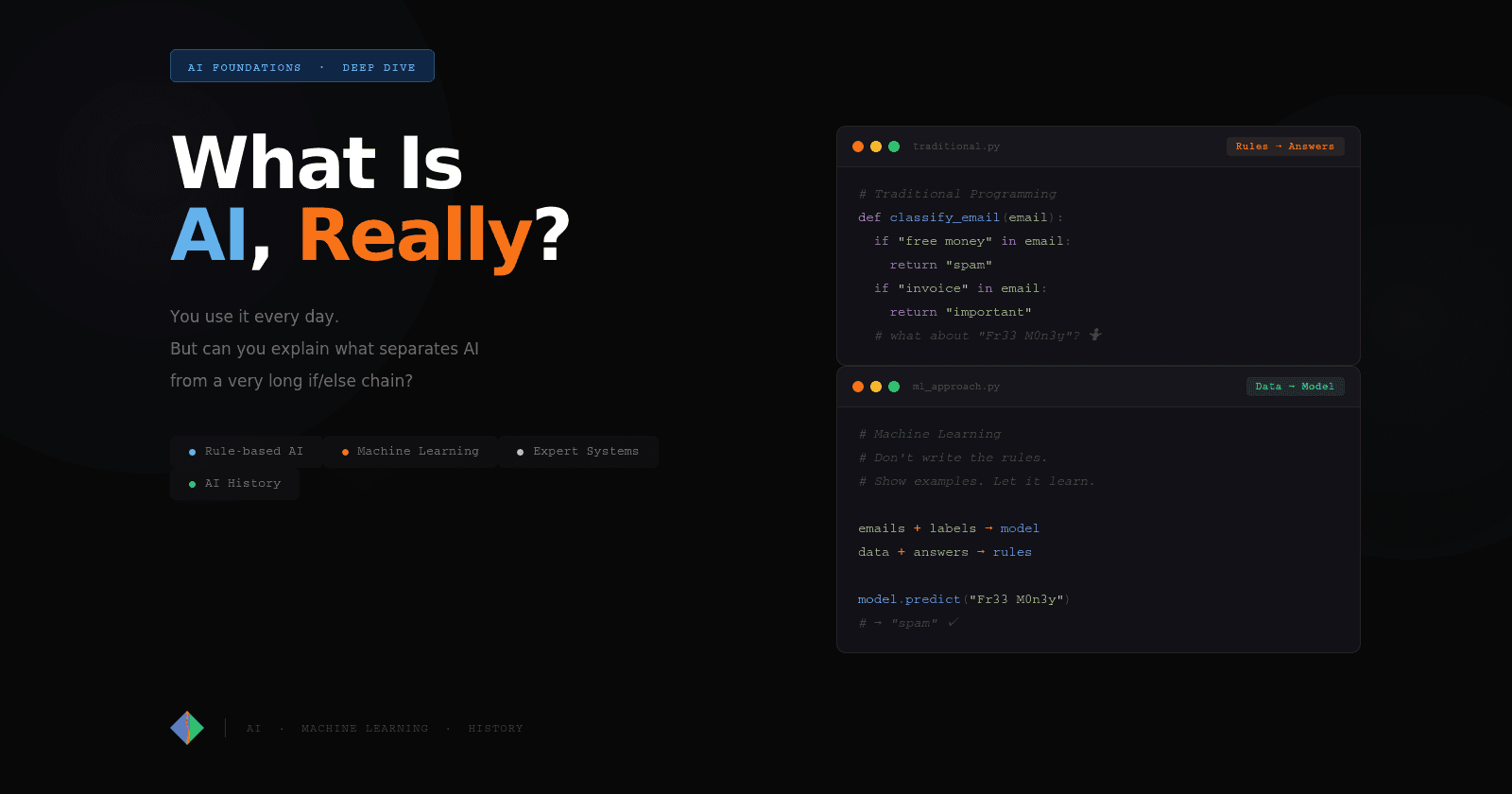
This is the core insight of Machine Learning and it represents a fundamental inversion of how we'd been thinking about programming:
| Traditional Programming |
Machine Learning |
| Rules + Data = Answers |
Data + Answers = Rules (called a "model") |
You stop writing the logic. You show the system thousands or millions of examples of correct behavior, and it figures the logic out itself. The patterns it discovers are encoded not as readable rules but as a mathematical function, a model, with millions of numerical parameters shaped by the training process.
This matters because it sidesteps the core problem of rule-based AI. You don't need to know what patterns to look for. You don't need to enumerate edge cases. You don't need to update a rulebook when the world changes, you retrain on new data.
It also means AI became practical for problems that were previously untouchable: recognizing faces in photos, understanding spoken language, detecting fraud in behavioral patterns, predicting which customers which churn. These problems share a common trait: the patterns are real, but they're too complex and too variable for any human to write rules for. Machine Learning finds those patterns automatically.
The explosion of internet-scale data in the 2000s and 2010s was the fuel that made this practical. Suddenly there were billions of labeled images, text documents, and behavioral logs to train on. Machine learning didn't change. The data did.
The Full Picture: AI Is a Family, Not a Thing
Here's the mental model I would like you to take away from this article:

Every node in that tree is legitimately "AI". They're all attempts to make machines do things that normally require human intelligence. But they work completely differently, they're good at completely different things, and they fail in completely different ways.
When you're building software in 2026, this what those levels mean practically:
Rule-based systems are still everywhere, and often the right choice. Input validation, business logic, compliance rules, routing decisions with clear thresholds. If the logic can be written explicitly and won't change constantly, write the rule. Don't reach for ML when an if/else does the job.
Classical Machine Learning is your tool for structured prediction problems: fraud detection, churn prediction, recommendation engines, demand forecasting. Fast, interpretable enough for business stakeholders, and doesn't require a GPU cluster.
Deep Learning is what you reach for when the input is raw and unstructured: images, audio, raw text at scale. It learns the features itself, which is the key difference from classical ML.
Generative AI via LLMs (GPT-5, Claude, Gemini) is what you're building on when you call an API and ask a model to write, summarize, classify, translate, or reason in natural language. It's deep learning at enormous scale, pre-trained on internet-scale data and made accessible via a simple API.
The Question You Should Always Ask
The next time someone says "we're using AI for this," ask: which kind?
Is this a rule engine with good marketing copy?
Is this a classical ML model making predictions from structured data?
Is this a deep neural network trained on raw input?
Is this a pre-trained LLM being called via API?
Each answer leads to completely different conversations about data requirements, cost, latency, explainability, failure modes, and maintenance burden.
You now have the vocabulary to ask that question precisely, and to understand the answer.
Sources
The historical claims in this article are drawn from the following verifiable sources:
Next in the series we go inside the learning process itself: What a model really is, how training works, and why "garbage in, garbage out" is more dangerous than it sounds.