In Part 1, we established that "AI" is a goal, not a method and that Machine Learning is the dominant approach for reaching that goal today. We said ML systems learn from data instead of following hand-coded rules.
But what does "learning" actually mean for a machine? What is a model, physically? What happens during training? And why does a model that scores 99% on its training data sometimes completely fall apart in the real world?
This article attempts to answer all of that precisely, not vaguely. By the end, you'll have the vocabulary and mental models to have sharp technical conversations about ML, and to make informed decisions about when and how to use it in your applications.
The Fundamental Flip
Let's start by sharpening something from Part 1 into something you can actually use.
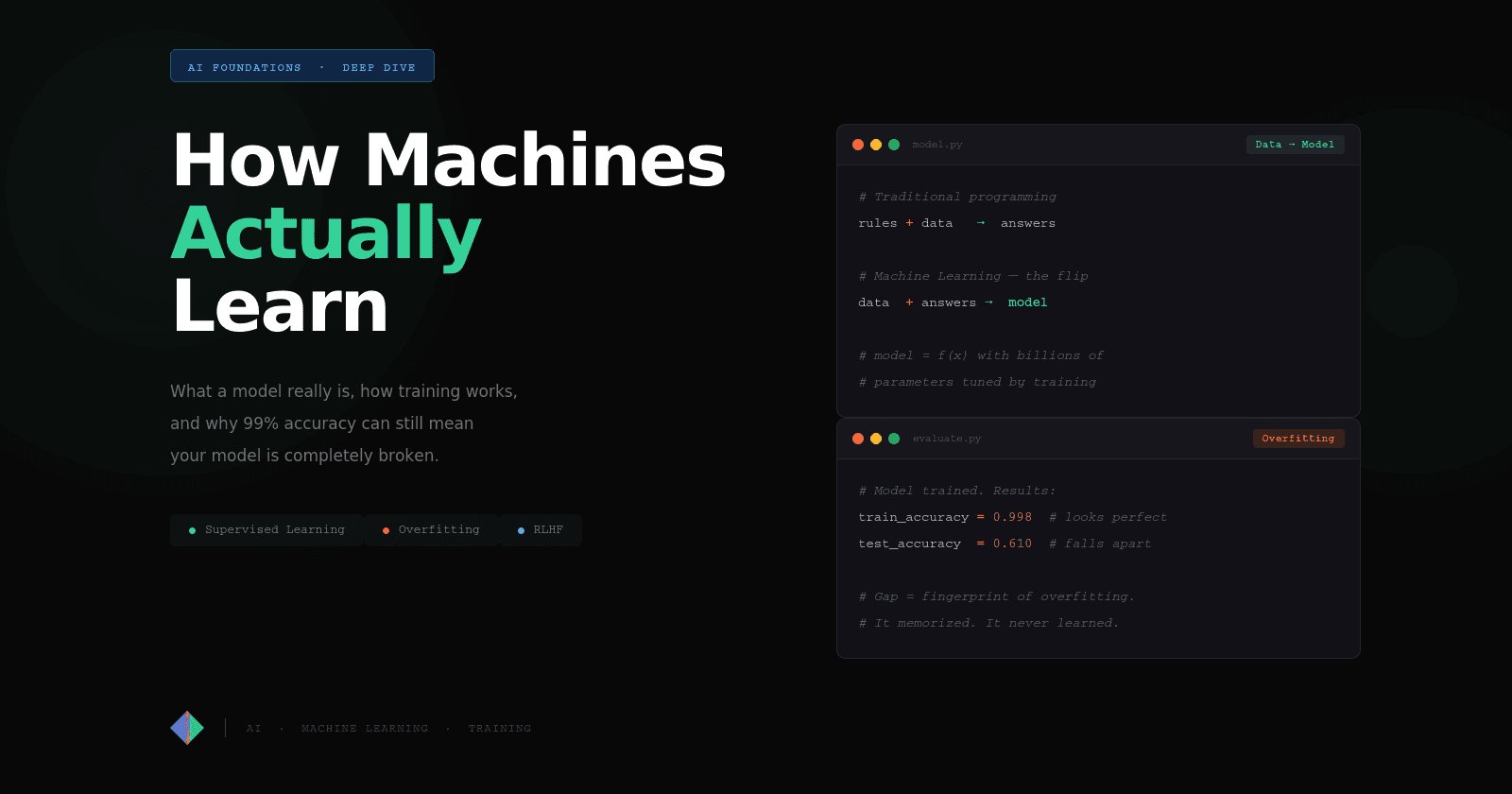
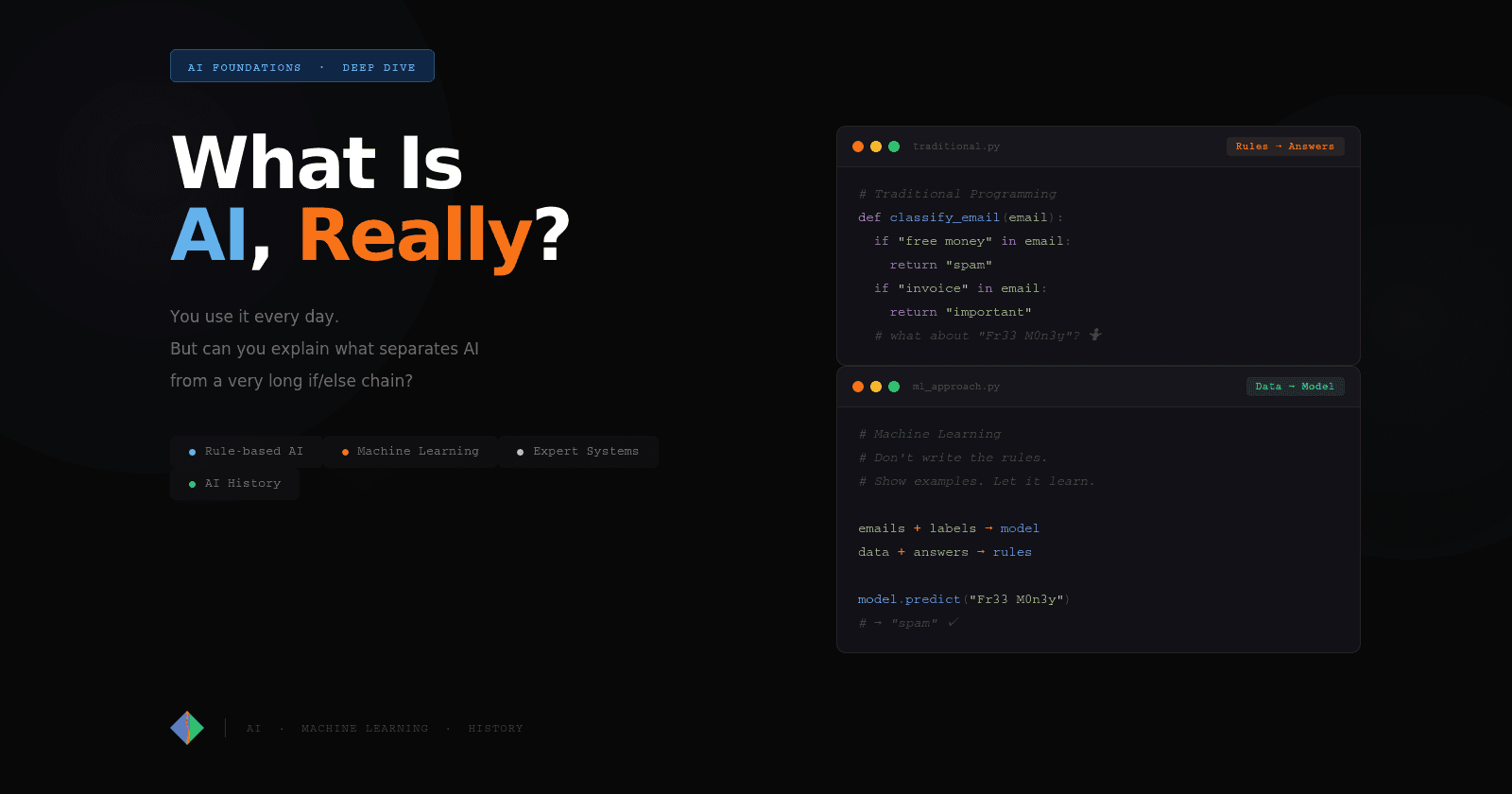
In traditional programming, you write the logic:
Rules + Data = Answers
You define the conditions. The program applies them. Every decision the software makes traces back to something you explicitly wrote.
Machine Learning inverts this completely:
Data + Answers = Rules (called a "model")
You don't write the logic. You provide examples of correct behavior, lots of them, and the system discovers the logic itself. That discovered logic gets encoded in a mathematical object called a model, and from that point on, you use the model to produce answers for new inputs.
This flip has profound implications. It means ML can tackle problems where the rules are too complex, too variable, or simply impossible for a human to articulate, like recognizing a face, understanding the sentiment of a sentence, or predicting which customer is about to cancel their subscription.
What Is a Model, Actually?
This is the question most introductions skip over, and it's where a lot of my confusion started.
A model is a mathematical function with a large number of adjustable numerical parameters. That's it. Nothing more mystical than that.
When you train a model, you're running an optimization process that adjusts those parameters until the function produces correct outputs for your training data. Once training is complete, the parameters are frozen. That frozen function, with all its tuned parameters, is your model.
When you call the Azure OpenAI API and get a response from GPT-5, you're passing your input through a function with hundreds of billions of parameters, tuned by training on an enormous corpus of text. The "intelligence" isn't magic. It's math, at scale, shaped by data.
This also explains something that trips up developers early on: you can't "edit" a model the way you edit code. There are no rules to find and update. The knowledge is distributed across billions of numbers simultaneously. When the world changes (customer language evolves, fraud pattern shift, new product launch...), you don't patch the model. You retrain it on new data.
The Three Types of Machine Learning
Under the ML umbrella, there are three fundamentally different learning paradigms. Which one you use depends entirely on the shape of your data and what you're trying to accomplish.
1. Supervised Learning
The most common type, and what most people mean when they say "Machine Learning."
You provide the system with labeled examples, input/output pairs where the correct answer is already known. The system learns to map inputs to outputs by minimizing its mistakes on the label data.
Input: Email test
Label: "spam" or "not spam"
Goal: Learn to correctly label new, unlabeled emails.
The two main flavors:
Classification: Predicting a category ("spam/not spam", "fraud/legitimate", "cat/dog/bird")
Regression: Predicting a continuous number (house price, customer lifetime value, temperature tomorrow)
Real examples you interact with daily: spam filters, credit scoring, fraud detection, medical diagnosis models, image recognition, and at massive scale the pre-training of large language models.
2. Unsupervised Learning
No labels at all. You hand the system raw data and ask it to find structure.
Input: 5 million customer purchase histories
Labels: None
Goal: Discover natural groupings, patterns, or anomalies in the data
The system isn't told what to look for, it discovers it. This makes unsupervised learning valuable for exploratory analysis, where you don't know in advance what categories exist in your data.
Common applications:
Clustering: "These five types of customers exist in your data"
Anomaly detection: "This transaction looks nothing like normal behavior"
Dimensionality reduction: Compressing high-dimensional data into a form humans can visualize or models can process more efficiently.
3. Reinforcement Learning
No dataset at all. Instead, an agent takes actions in an environment, receives rewards and penalties, and learns over time which behaviors maximize cumulative reward.
The training loop look like this.

Think of training a dog: you don't give it a rulebook. You give it treats when it does the right thing and corrections when it doesn't. Over thousands of repetitions, the dog learns which behaviors are rewarded. Reinforcement learning is exactly this, but for software agents.
This is how game-playing AI systems like AlphaGo were built, not by encoding the rules of Go explicitly, but by having the agent play millions of games against itself and learn which moves tend to win.
The connection to what you build on every day
Bear this in mind: Reinforcement Learning is how the large language models you use via Azure OpenAI API were made useful, not just capable.
A model pre-trained on internet text is extraordinarily knowledgeable, but it's also unpredictable, sometimes harmful, and often unhelpful in conversation. The technique that fixes this is called RLHF - Reinforcement Learning from Human Feedback.
In RLHF, human evaluators rate the model's responses. Those ratings train a separate "reward model" that scores outputs based on human preferences. The main LLM is then updated using reinforcement learning to maximize that reward, producing response that humans find helpful, safe, and truthful.
This three-step process: pre-training on data, supervised fine-tuning on examples, then RLHF is what turned GPT-3 (impressive but erratic) into ChatGPT (useful in conversation). Every major LLM you interact with today has been through some variant of this pipeline.
Training vs. Inference: Two Completely Different Operations
These terms get used interchangeably by non-practitioners, but they describe fundamentally different things with different cost profiles and infrastructure requirements.
Training is the process of creating a model. You feed it data, run the optimization algorithm, adjust the parameters, repeat. This is computationally expensive: training GPT-4 reportedly cost tens of millions of dollars in compute. You do it once (or periodically when retraining). It requires GPUs or TPUs in quantity.
Inference is the process of using a trained model to make predictions on new data. This is what happens every time you call client.chat.completions.create(...) in your application. Much cheaper per operation than training, but you do it millions of times in production.
The practical implication for you as a developer: you will almost never train a model from scratch. You will almost always do one of these:
Call a pre-trained model via API (Azure OpenAI for example)
Fine-tune a pre-trained model on your specific data (a middle ground)
Use a pre-trained model as-is, guided by prompts (prompt engineering)
Training from scratch is the domain of AI research labs and large enterprises with specialized data and budget. API-based inference is the domain of application developers, which is where you and I operate.
Overfitting: The Most Dangerous Silent Failure in ML
Here's a scenario you need to really understand, because it will affect every ML decision you make.
You train a fraud detection model on 100,000 historical transactions. After training, you test it on those same 100,000 transactions: 99.7% accuracy. Impressive! You deploy it.
Three months later, your fraud team tells you the model is catching less fraud than their old rules engine. What happened?
Overfitting. The model didn't learn the pattern of fraud. It memorized your 100,000 training examples, including their noise, their quirks, their statistical accidents. When it encountered real-world fraud that looked slightly different from the training data, it had no answer.
As Google's Machine Learning documentation describes it directly: "Overfitting means creating a model that matches (memorizes) the training set so closely that the model fails to make correct predictions on new data. An overfit model is analogous to an invention that performs well in the lab but is worthless in the real world"
The counterpart to overfitting is generalization: the ability to make correct prediction on data the model was never trained on. Generalization is the entire point of ML. A model that only works on its training data is useless. A model that has truly learned the underlying pattern will work on data it's never seen.
How to detect overfitting
The standard practice is to split your data into three sets before training ever begins:
Training set (~70-80%): what the model learns from
Validation set (~10-15%): used during training to detect overfitting early
Test set (~10-15%): help completely aside and used only once at the end to evaluate the final model
If your model scores 99% on the training set and 61% on the test set, that gap is the fingerprint of overfitting. A well-generalized model will have similar scores on both.
What causes it, and how to prevent it
Overfitting happens when a model has too much capacity relative to the amount of training data. It has enough parameters to memorize individual examples rather than learn general patterns.
The fixes:
More training data: the most reliable solution. More examples force the model to learn patterns that hold broadly, not quirks of a small dataset.
Simpler model: fewer parameters means less capacity to memorize.
Regularization: mathematical penalties that discourage the model from assigning extreme importance to any single feature.
Early stopping: halt training before the model starts memorizing, guided by validation set performance.
Dropout: a deep learning technique that randomly disables neurons during training, preventing the network from relying on any one path.
The Honest Limitation of Machine Learning
As important as knowing what ML can do is knowing what it can't. These aren't edge cases, they're practical constraints that shape architectural decisions you'll make constantly.
ML cannot explain its reasoning. A fraud detection model can flag a transaction as suspicious, but it can't tell you why in human-understandable terms. The "reasoning" is distributed across millions of numerical parameters. This creates real problems in regulated industries (banking, healthcare, legal) where decisions must be explainable and auditable.
ML is only as good as its training data. The model learns whatever patterns exist in the data, including biases. A hiring model trained on historical decisions from a company that historically favored certain demographics will learn to replicate that bias. Garbage in, garbage out, but worse: biased data produces biased models that discriminate at scale and at speed.
ML doesn't know what it doesn't know. A model trained on data from 2022 has no concepts of events, products, or language patterns from 2024. It will confidently mis-classify inputs that fall outside its training distribution with no warning, no error, and no uncertainty expressed. This is why LLMs hallucinate: they produce confident-sounding outputs even when they have no reliable training data for the input.
ML requires data, a lot of it. Supervised learning needs labeled examples. Getting those labels is expensive: human annotators, historical records, careful data engineering. For many problems, the data collection and labeling is more work than the modeling itself.
ML models degrade over time. The world changes. Customer behavior shifts, language evolves, fraud patterns adapt, product lines expand. A model trained on last year's data will drift from reality as the distribution of inputs changes.
This is called data drift or concept drift, and managing it in production is a continuous engineering problem, not a one-time deployment.
The Essential Vocabulary
Before we move forward, here's every term from this article defined precisely:
| Term |
Meaning |
| Model |
A mathematical function with tunable parameters, shaped by training data |
| Training |
The process of optimizing a model's parameters to fit training data |
| Inference |
Using a trained, frozen model to make predictions on new data |
| Features |
The input variables fed into a model (e.g. word counts, pixel values, transaction amount) |
| Labels |
The correct output values in supervised learning (e.g. "spam", "fraud", "$450,000") |
| Unsupervised learning |
Finding structure in unlabeled data |
| Reinforcement learning |
Learning through trial, error, and reward signals |
| RLHF |
Reinforcement Learning from Human Feedback: how LLM are made helpful and safe |
| Overfitting |
When a model memorizes training data and fails to generalize |
| Generalization |
When a model correctly handles data it was never trained on |
| Data drift |
When real-world input distribution shifts away from the training distribution |
What This Means When You're Building
Most developers working with AI in 2026 are not training models, they're building applications on top of pre-trained models accessed via API. But understanding ML deeply changes how you build those applications:
You understand why prompt engineering works (you're guiding inference, not retraining)
You understand why RAG (Retrieval-Augmented Generation) exists as training data has a cutoff; the model doesn't know your data
You understand why LLMs hallucinate (overfitting's conceptual cousin, confident outputs outside the training distribution)
You understand why temperature matters (controlling the randomness of the model's output distribution)
You know when not to use an LLM, and when a simple classical ML model or even a rules engine is the correct tool
That last point is worth dwelling on. An LLM costs orders of magnitude more per inference than a logistic regression model. For structured prediction on tabular data (churn prediction, fraud scoring, demand forecasting), a classical ML model will likely outperform an LLM and cost a fraction of the price.
Understanding the full ML landscape lets you make those calls.
Sources
Next in the series, we open the black box and show exactly what's happening inside a neural network: neurons, weight, biases, and the training loop that makes it all work.