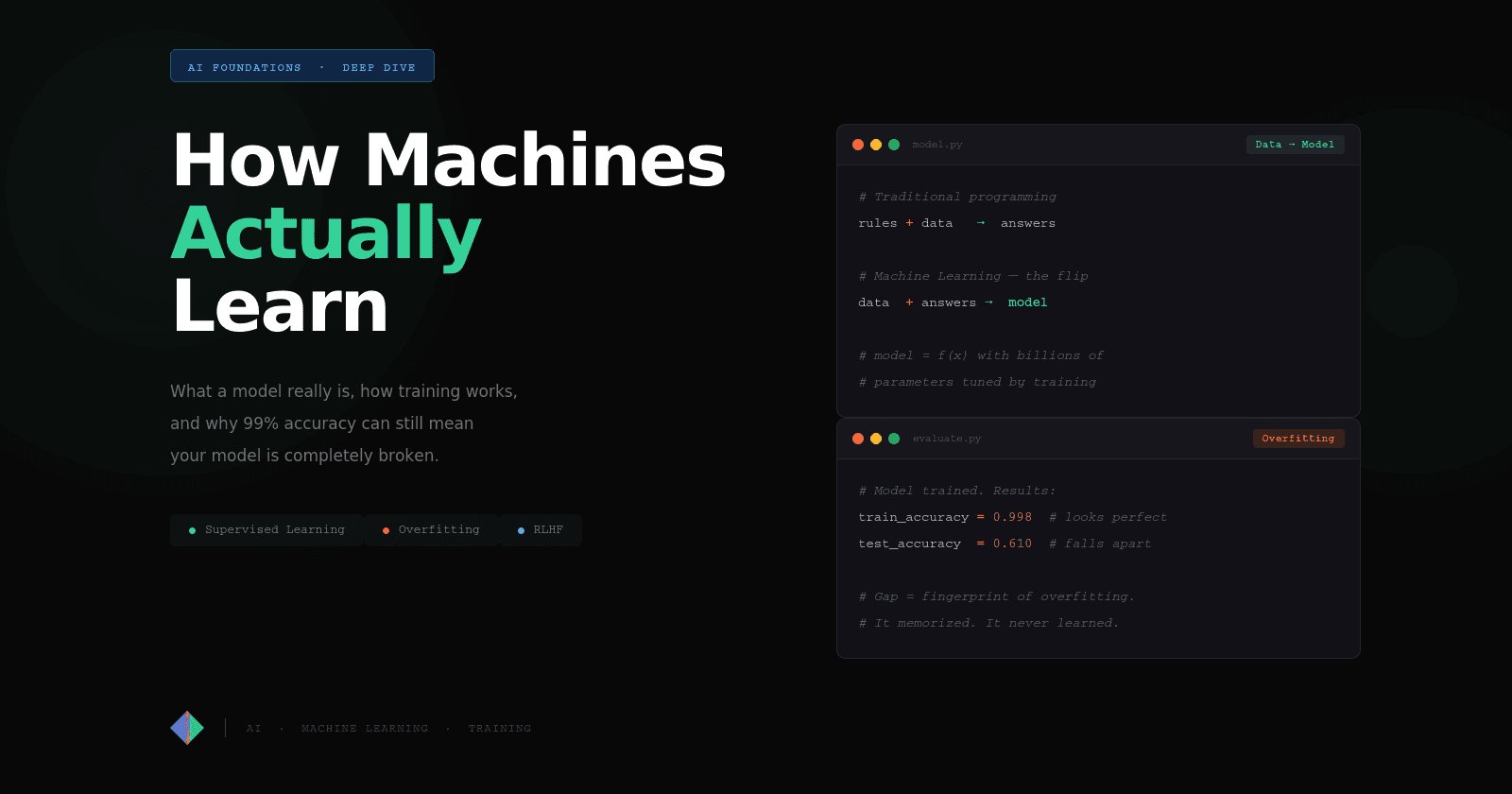
Why Python Makes you "Close" Things (And What Happens When You Don't)
Every open() is a debt. Here's what happens when you don't pay it back
Coming from JavaScript/TypeScript, I thought I understood resource management. You fetch(), you await, you move on. Node.js handles the rest, right?
Then I started writing Python seriously, and I kept on seeing this part everywhere:
with open("data.txt", "r") as file:
content = file.read()
I knew how to use it. Always writing the same bit of syntax, it works. But I had no idea why it existed, or what happened if I skipped it.
It turns out a lot can go wrong. And the worst part is that it won't blow up immediately. It will fail silently, in production, at 2am on a Saturday.
This article is about understanding the problem that Python's with statement was built to solve. We'll get to with in the next article. First, let's talk about what happens when things go wrong.
Your Program Borrows Things from the OS
When your Python program wants to read a file, it can't just reach into the filesystem directly. It has to ask the operating system nicely.
The OS responds by opening the file and handing your program a file descriptor, a small non-negative integer that acts as a reservation ticket. Think of it like the numbered ticket you get at a deli counter. The ticket isn't the sandwich. It's just proof that you're in the queue and the deli is holding your order.
file = open("notes.txt", "w")
print(file.fileno()) # prints something like 3, 4, or 5
Numbers 0, 1, and 2 are permanently reserved by the OS for every process:
| Descriptor | Name | What it is |
|---|---|---|
0 |
stdin |
Keyboard input |
1 |
stdout |
Normal print output |
2 |
stderr |
Error output |
So the first file you open typically gets descriptor 3, the next gets 4, and so on.
Here is the critical part: the OS keeps a table of open file descriptors per process, and that table has a fixed size. On most Linux systems, the default limit is 1024.
import resource
soft_limit, _ = resource.getrlimit(resource.RLIMIT_NOFILE)
print(f"Max open files: {soft_limit}") # typically 1024
Once all 1024 slots are taken, any new open() call raises:
OSError: [Errno 24] Too many open files
That ticket counter fills up, and the deli stops taking orders.
The Leak You Don't See Coming
Here's where it gets sneaky. A resource leak doesn't announce itself. It builds up quietly until the system hits its limit, then it explodes.
Consider this function that processes a batch of files:
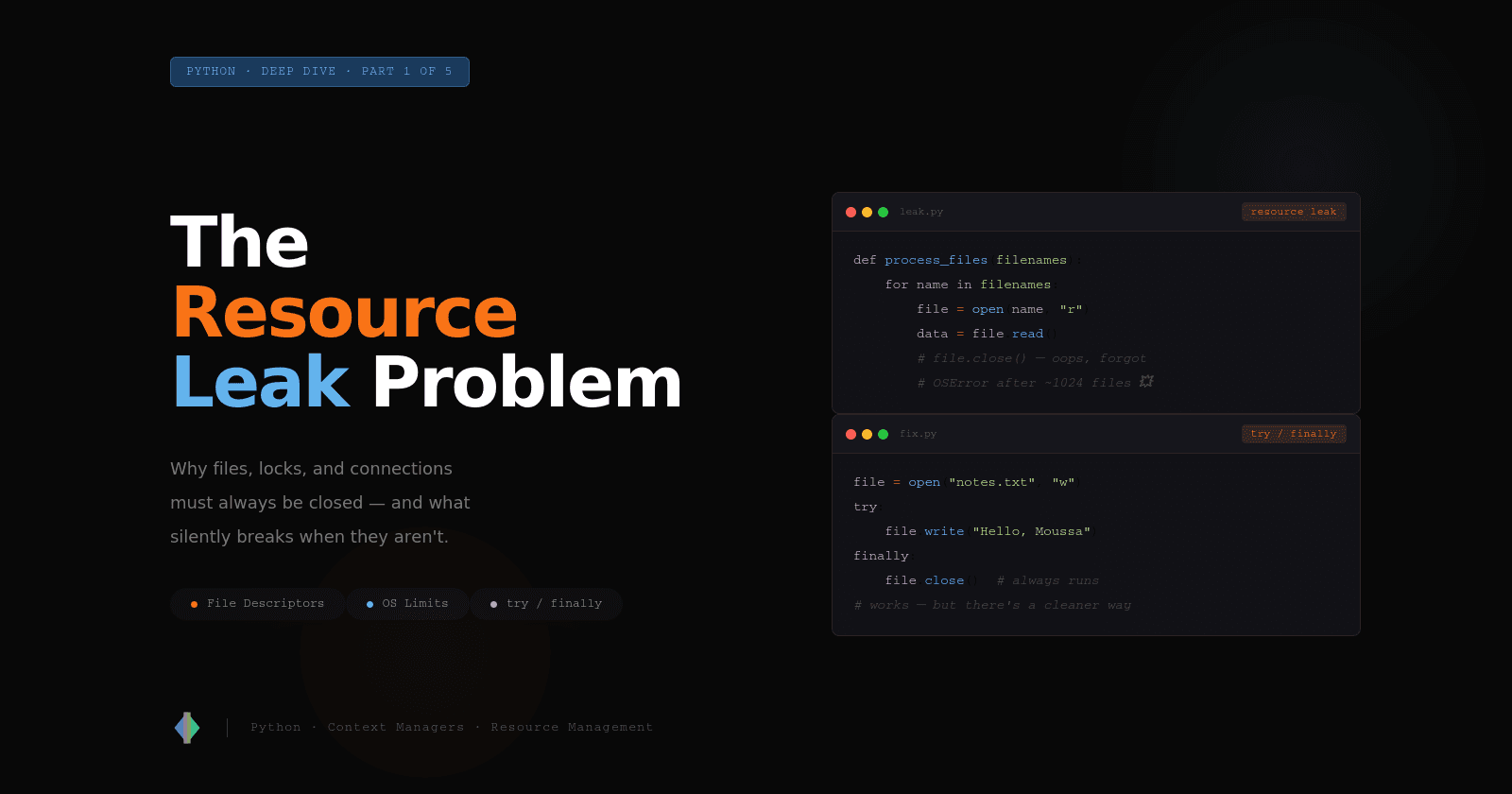
def process_files(filenames):
for name in filenames:
file = open(name, "r")
data = file.read()
process(data)
# oops — forgot file.close()
This works perfectly for the first 1,021 files. Then on file 1022, crash 💥. And the error message points at the open() call, not at the missing close() three lines earlier. Good luck debugging that at 2am!
Let's make it concrete. Here's a script that deliberately leaks file descriptors:
import os
files = []
count = 0
try:
while True:
f = open("test.txt", "w")
files.append(f) # keep a reference so it's not garbage collected
count += 1
except OSError as e:
print(f"Failed after {count} open files: {e}")
It's Not Just Files
File descriptors are the most visible example, but the same problem applies to any resource with a limited supply:
Network connections: databases, APIs, and servers all have connection limits. Leave connections open and you'll eventually see Too many connections errors from your database, with perfectly healthy-looking application code.
Locks: This one is nastier that a file leak. If your code requires a threading lock and then throws an exception before releasing it, the lock stays held forever. Every other thread waiting on it will wait forever too. Your application freezes. No error message, just silence.
import threading
lock = threading.Lock()
def transfer_funds(amount):
lock.acquire()
if amount > get_balance():
raise ValueError("Insufficient funds") # 💥 lock never released
deduct(amount)
lock.release() # never reached if the check above raises
Call transfer_funds() with an invalid amount once, and your entire application deadlocks. Every subsequent call to any function that tries to acquire that lock will hang. Congratulations, you've built a very expensive paperweight 😄.
The Data Corruption You Don't Expect
There's another flavor of resource leak that's even more surprising: unflushed writes.
When you write to a file, Python doesn't immediately send those bytes to disk. It buffers them in memory first for performance. The buffer gets flushed to disk with it fills up, when you call .flush(), or crucially, when you call .close().
If your program crashes before .close() is called, the buffer is discarded. The data never makes it to disk.
file = open("important_data.txt", "w")
file.write("Transfer $10,000 to account 9982")
raise Exception("something went wrong")
file.close() # never reached
Open important_data.txt after running this. Empty!!!
Those bytes were sitting in a memory buffer, and when the process died, they went with it.
Let's make it even more dramatic:
import os
file = open("test.txt", "w")
file.write("This will never make it to disk")
os._exit(1) # hard kill — skips all cleanup
Check test.txt after running that. Empty file. Zero bytes written.
Won't the Garbage Collector Handle It?
Coming from JavaScript, this was my first instinct too. GC handles memory, but does it handle files too?
Sometimes. CPython (the standard Python implementation) uses reference counting: when an object's reference count drops to zero, it gets cleaned up immediately, which includes closing the file:
def read_data():
file = open("notes.txt", "r")
return file.read()
# file goes out of scope here
# CPython closes it immediately — but only because of reference counting
But here's the problem: this is an implementation detail of CPython, not a guarantee of the Python language. PyPy, Jython, and other Python implementations use different garbage collectors that don't clean up immediately. Even in CPython, circular references can delay cleanup indefinitely.
The Python documentation is explicit about this:
"It is good practice to use the
withkeyword when dealing with file objects. The advantage is that the file is properly closed after its suite finishes, even if an exception is raised at some point."
Don't rely on GC to close your files. It's like assuming someone else will wash your dishes. Maybe they will. Maybe they won't. You'll find out at the worst possible time.
The Manual Fix, And Why It's Not Enough
Once you understand the problem, the fix seems obvious: use try/finally.
finally blocks always run, whether the code inside succeeded, raised an exception, or even hit a return statement.
file1 = open("input.txt", "r")
try:
file2 = open("output.txt", "w")
try:
data = file1.read()
file2.write(data.upper())
finally:
file2.close()
finally:
file1.close()
This is correct but exhausting to write and read. There has to be a better way. Don't you think so? 🤔
There Is a Better Way
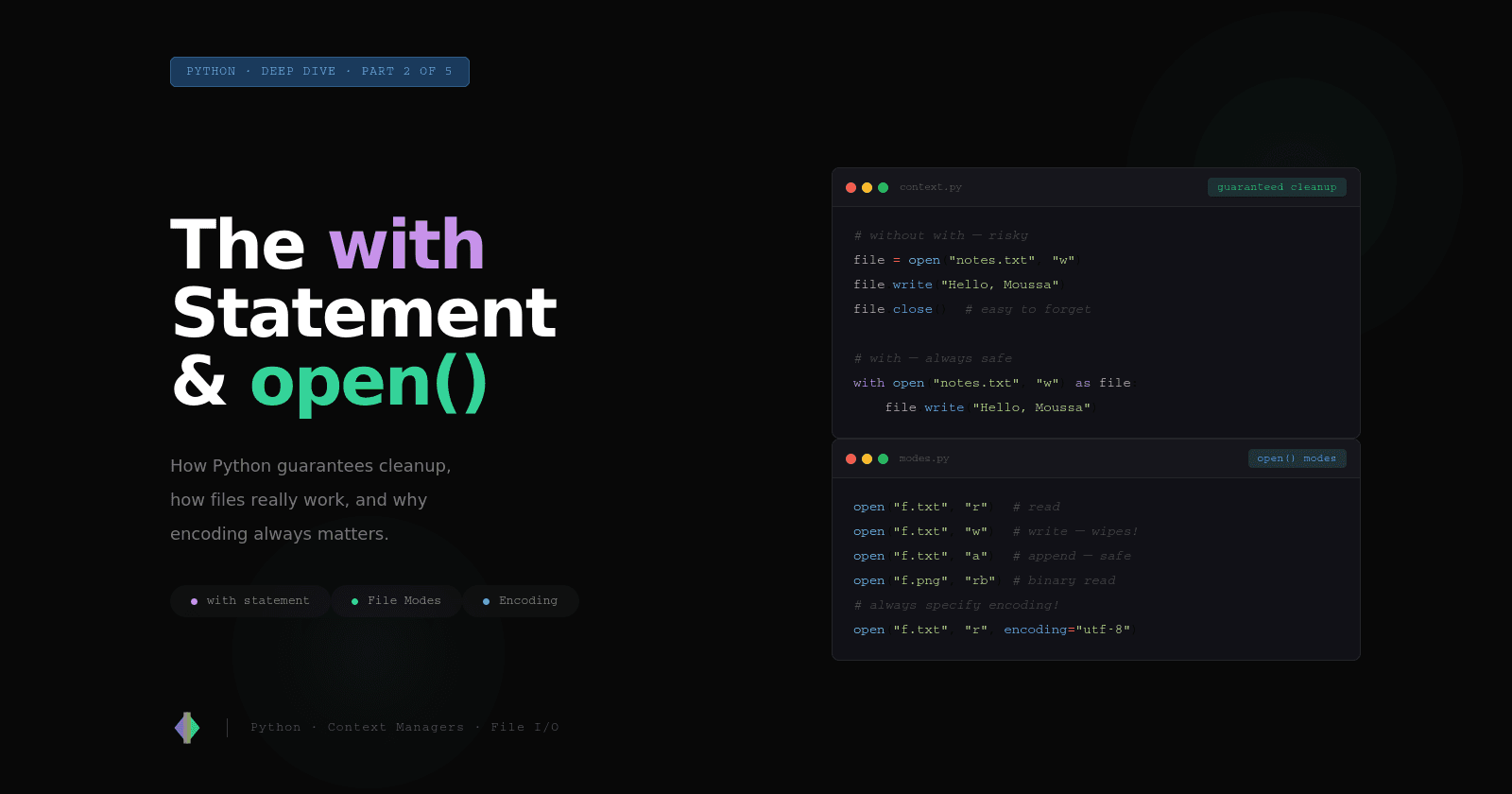
Python 2.5 introduced the with statement (via PEP 343) specifically to solve this problem. It packages the try/finally pattern into a clean, reusable interface that's impossible to forget.
The same two-file example from above becomes:
with open("input.txt", "r") as file1, open("output.txt", "w") as file2:
data = file1.read()
file2.write(data.upper())
# both files are closed here — automatically, always
No nesting, no finally. No way to forget to cleanup. The same guarantee, with none of the ceremony.
That's what context managers are, a Python-native way to say: "when this block exits, run this cleanup, no matter what."
The Mental Model to Take Away
Every resource your program borrows from the OS need to be returned:
Open a file, close it
Acquire a lock, release it
Open a connection, close it.
The problem isn't that developers don't know this. It's that code between acquiring and releasing can fail, and when it does, the cleanup gets skipped.
try/finally is the manual solution. Context manager is the automatic one.
In the next article, we'll look at exactly how the with statement works, go deep on open(), and start seeing how Python's most common operation, reading and writing files, becomes foolproof with context managers.
Acronyms Used in This Article
OS — Operating System. The software that manages hardware resources and provides services to programs. On most servers, this is Linux.
GC — Garbage Collector. The part of a language runtime responsible for automatically reclaiming memory that's no longer in use.
PEP — Python Enhancement Proposal. A design document used by the Python community to propose and discuss new language features. PEP 343 is the one that introduced the
withstatement.
Thank you for reading 🙂.
This is Part 1 of 5 in the Python Context Managers Series.
Next up: Part 2 - The
withStatement andopen()in Depth.